
Desarrollo Web en Equipo: Como usar GIT y no morir en el intento
¿Sigues usando el copia-pega para hacer las copias de seguridad del código de tus proyectos? Un gatito muere cada vez que haces Crtl+C - Ctrl+V.
Aprender a usar GIT
En primero de Informática en la Universidad dan ciertas cosas por sabidas y otras te las explican de pasada, como es el caso de las copias de seguridad. Hasta que borras, sin quererlo, el código de una práctica el día antes de la entrega final y te tienes que quedar hasta las 5 de la mañana para recuperar el trabajo realizado como buenamente puedes. Es en ese momento cuando piensas: ¿por qué no tendré una copia de seguridad de esto?
A partir de este momento, tienes siempre un par de copias de seguridad de tus trabajos. Para cosas pequeñas como prácticas de la facultad no montas un sistema muy elaborado si no que simplemente haces copias completas de tu código en un disco duro externo o un lápiz USB. Incluso conozco casos en los que la gente se enviaba correos electrónicos a si mismos con los proyectos en ficheros comprimidos adjuntos.
Sin embargo, cuando se cuenta con un equipo de desarrollo web como el que existe en Neozink, donde varias personas trabajan en el código de los proyectos, es necesario disponer de una herramienta que permita organizar y tener controlado el código de todos y cada uno de los proyectos de una forma eficiente. Nosotros utilizamos GIT, un sistema de control de versiones diseñado por Linus Torvalds (responsable del nacimiento y mantenimiento del núcleo del sistema operativo Linux) y lo combinamos con el software SourceTree, una herramienta de navegación y visualización para el historial de GIT.
Con estas dos piezas de software manejamos y controlamos todo el código de cada uno de nuestros proyectos.

Básicos GIT: servidor y operaciones principales
La pieza central de un sistema de control de versiones como GIT es el servidor, que es donde está almacenado todo el contenido de la organización. Los distintos miembros del equipo de desarrollo se conectan al servidor para hacer copias locales del código o para enviar los cambios realizados en el código. Estas operaciones se conocen como “push” (envío de cambios en el código al servidor) y “pull” (volcado a la máquina local del código del servidor).
Cuando un miembro del equipo comienza a trabajar en un proyecto, el primer paso es la clonación del repositorio en su máquina de trabajo desde el servidor. Para ello ejecutará una operación “clone”, que descargará una copia completa del código desde el servidor a su máquina local. Desde ese momento, el desarrollador podrá trabajar en su máquina realizando cambios sin que estos afecten al código del servidor.
En el momento en que los cambios son estables y se ha alcanzado la funcionalidad deseada, el desarrollador consolidará los cambios realizados a través de la operación “commit”. Esta operación indica que los cambios se han almacenado aunque, de momento, no estarán disponibles en el servidor para el resto de miembros del equipo. Para hacer que los cambios se envíen al servidor será necesario ejecutar la acción “push”, que publica los cambios en el servidor y hace que estos estén disponibles para el resto del equipo.
Si alguno de los desarrolladores quiere contar con el nuevo código en su máquina de trabajo deberá ejecutar una acción “pull” sobre el servidor, que provoca la descarga de los cambios enviados al servidor por el otro miembro del equipo.
¿Qué son las ramas en GIT?
El concepto principal de un repositorio GIT es la rama. Una rama representa la evolución del código de un proyecto y dentro de cada rama habrá varios puntos o commits en los que se haya almacenado información en el servidor.
Un repositorio GIT se compone de un conjunto de ramas que se relacionan entre si para componer el código del proyecto. Los puntos en los que las ramas convergen representan aquellos momentos en los que se vuelca el contenido de una rama en otra, para traspasar las funcionalidades o mejoras realizadas.
En base a los tipos de proyectos que se realizan dentro de la organización y la estructura del equipo de desarrollo presente es necesario escoger cómo se van a manejar las ramas, lo que se conoce como el modelo de ramas del repositorio.
¿Qué modelo de ramas elegir?
El modelo de ramas elegido marcará el funcionamiento interno del equipo de la misma forma que la táctica de un equipo de fútbol (4-4-2, 4-3-3, 3-5-2, etc.) marca el desarrollo de un partido. Por lo tanto, esta no es una decisión que haya que tomar a la ligera.
Nosotros, después de analizar las distintas opciones existentes, nos hemos decantado por utilizar el siguiente modelo:
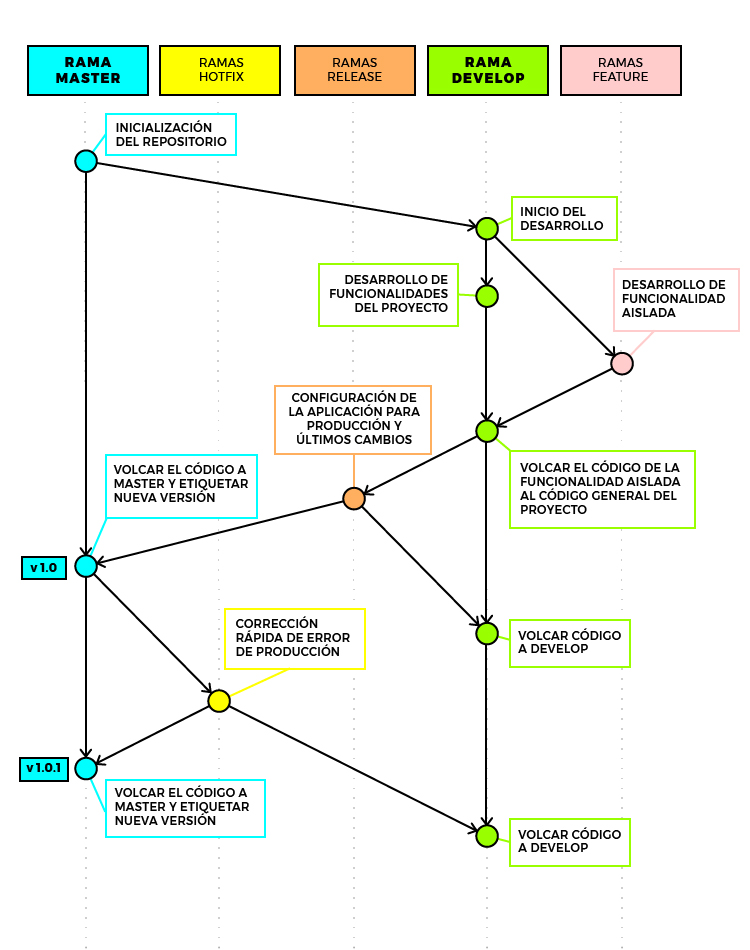
- Rama master: la rama principal del proyecto. Sobre esta rama no se hace trabajo, solamente se utiliza como copia de las versiones del software que se despliegan. Esta rama estará configurada con los valores de configuración para el entorno del servidor de producción.
- Rama develop: la rama de trabajo diario del proyecto. La mayor parte de los cambios que se realizan sobre el código del proyecto se realizan en esta rama. Esta rama estará configurada con los valores de configuración para los entornos de desarrollo.
- Ramas feature: cuando se necesita desarrollar una funcionalidad aislada en un proyecto se abre una rama de este tipo y se realiza el desarrollo completo de dicha funcionalidad en esta rama. Una vez completado el desarrollo, se vuelca la rama dentro de la rama develop para incluir la nueva funcionalidad en el código del proyecto.
- Ramas release: cuando se va a realizar un despliegue de una versión del código en el servidor de producción se abre una rama de este tipo. Una vez abierta se hacen los cambios de configuración relativos al entorno de producción y se sube el código del proyecto al servidor. Cuando el despliegue se completa de forma satisfactoria, la rama release se vuelca a la rama master y se añade una etiqueta con el número de versión correspondiente.
- Rama hotfix: cuando se quiere solventar un error pequeño en el código que está desplegado en el servidor, se abre una rama de este tipo desde la rama master y se realizan los cambios pertinentes en ella. Una vez completados los cambios se vuelcan tanto en la rama develop como en la rama master, que se etiqueta con la nueva versión. En ese momento, el arreglo estará disponible en las dos ramas fundamentales del repositorio del proyecto.
Con este modelo de ramas, según se van realizando los cambios en el proyecto y desarrollando las distintas funcionalidades, se irá componiendo un gráfico en nuestro SourceTree que nos irá indicando como se relacionan las ramas entre si y cuál ha sido el camino que ha ido siguiendo el código hasta estar completo.
La pifié con unas modificaciones, ¿qué hago?
Como GIT es un sistema de control de versiones, si se da el caso de que hayas realizado unos cambios en el código que finalmente no sirven o no funcionan como era de esperar, no hay ningún problema. No es raro que a la hora de desarrollar un sistema o aplicación informática se realicen cambios en el código que, una vez probados en profundidad, hay que deshacer o retocar.
Los programas como Source Tree permiten, haciendo uso de comandos de GIT de forma sencilla a través de sus interfaces gráficos, volver a la versión anterior de un fichero, de tal forma que todos los cambios recientes se descartan por completo y se vuelve, de forma exacta, al estado anterior. Ya no será necesario que recorras los directorios de la copia de seguridad en busca del fichero correspondiente y traspases su contenido a la versión actual del código.
Conclusiones
Si has llegado hasta este punto del artículo pasando por todos los apartados habrás comprobado que utilizar un sistema de control de versiones cuando se trabaja en un equipo de desarrollo informático es ESENCIAL. No solo te permite tener el código seguro en el servidor en todo momento si no que cada miembro del equipo puede trabajar en local en su parcela sin estorbar al resto y luego juntarlo todo en una única versión de forma sencilla.
Además, un sistema de este tipo con sus ramas bien organizadas y etiquetadas permite replicar de manera exacta el entorno de producción del cliente, por lo que la detección de los posibles fallos en el servidor de producción es más sencilla.
Si por el contrario has hecho scroll para leer solamente el final te recomiendo que subas hasta el inicio del artículo y le des una oportunidad, quizás cambie tu forma de trabajar y contribuyas a que no sigan muriendo otros gatitos.